
In the recently released SeaTunnel 2.3.0 official version, the community self-developed engine SeaTunnel Zeta which has been under preparation for more than a year——is officially released, and it will be used as the default engine of SeaTunnel in the future, providing users with high throughput, low latency, reliable consistent synchronization job operation guarantee.
Why does SeaTunnel develop its synchronization engine? What is the positioning of the SeaTunnel Engine? How is it different from traditional computing engines? What is the design idea? What is unique about the architectural design? These questions will be answered in this article.
- Why develop our engine
- SeaTunnel Engine Positioning
- Design ideas
- Architecture design
- Unique advantages and features
- Current basic functions and features
- Future optimization plan
01 Why develop our engine
It was a year ago that the SeaTunnel community publicly stated for the first time that it would develop its engine. The reason why the team decided to develop a self-developed engine was that SeaTunnel's connector can run only on Flink or Spark, and Flink and Spark, as computing engines, have many unsolvable problems when integrating and synchronizing data.
Refer to: Why do we self-develop the big data synchronization engine SeaTunnel Zeta? https://github.com/apache/incubator-seatunnel/issues/1954
02 Design ideas
The general idea of engine design is as follows:
- Simple and easy to use, the new engine minimizes the dependence on third-party services, and can realize cluster management, snapshot storage, and cluster HA functions without relying on big data components such as Zookeeper and HDFS. This is very useful for users who do not have a big data platform or are unwilling to rely on a big data platform for data synchronization.
- More resource-saving, at the CPU level, Zeta Engine internally uses Dynamic Thread Sharing (dynamic thread sharing) technology. In the real-time synchronization scenario, if the number of tables is large but the amount of data in each table is small, Zeta Engine will Synchronous tasks run in shared threads, which can reduce unnecessary thread creation and save system resources. On the read and data write side, the Zeta Engine is designed to minimize the number of JDBC connections. In the CDC scenario, Zeta Engine will try to reuse log reading and parsing resources as much as possible.
- More stable. In this version, Zeta Engine uses Pipeline as the minimum granularity of Checkpoint and fault tolerance for data synchronization tasks. The failure of a task will only affect the tasks that have upstream and downstream relationships with it. Try to avoid task failures that cause the entire Job to fail. or rollback. At the same time, for scenarios where the source data has a storage time limit, Zeta Engine supports enabling data cache to automatically cache the data read from the source, and then the downstream tasks read the cached data and write it to the target. In this scenario, even if the target end fails and data cannot be written, it will not affect the normal reading of the source end, preventing the source end data from being deleted due to expiration.
- Faster, Zeta Engine’s execution plan optimizer will optimize the execution plan to reduce the possible network transmission of data, thereby reducing the loss of overall synchronization performance caused by data serialization and deserialization, and completing faster Data synchronization operations. Of course, it also supports speed limiting, so that sync jobs can be performed at a reasonable speed.
- Data synchronization support for all scenarios. SeaTunnel aims to support full synchronization and incremental synchronization under offline batch synchronization, and support real-time synchronization and CDC.
03 Architecture design
SeaTunnel Engine is mainly composed of a set of APIs for data synchronization processing and a core computing engine. Here we mainly introduce the architecture design of the SeaTunnel Engine core engine.
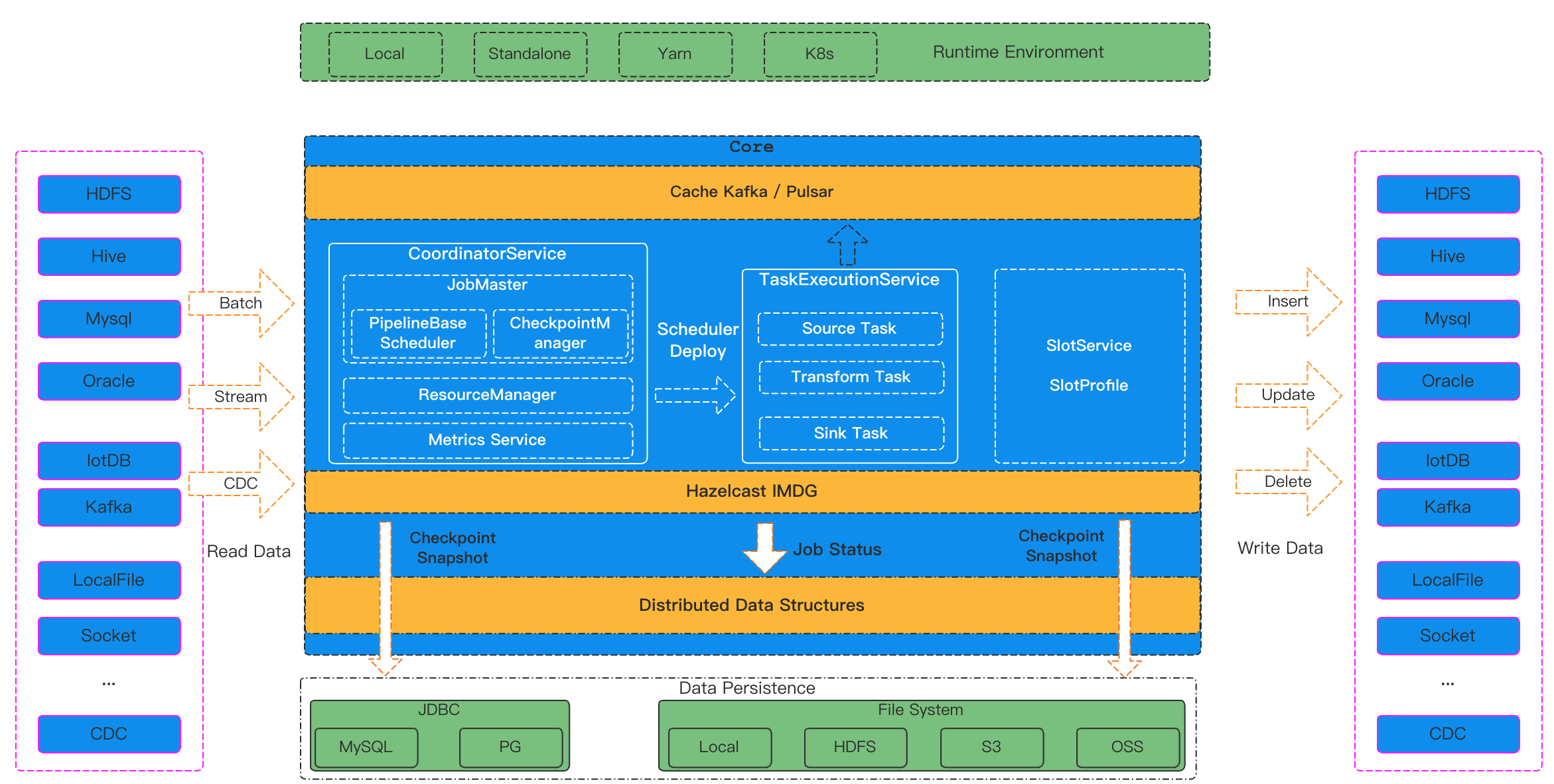 picture
picture
SeaTunnel Engine consists of three main services: CoordinatorService, TaskExecutionService, and SlotService.
Coordinator Service
CoordinatorService is the Master service of the cluster, which provides the generation process of each job from LogicalDag to ExecutionDag, and then to PhysicalDag, and finally creates the JobMaster of the job for scheduling execution and status monitoring of the job. CoordinatorService is mainly composed of 4 large functional modules:
- JobMaster is responsible for the generation process from LogicalDag to ExecutionDag to PhysicalDag of a single job, and is scheduled to run by PipelineBaseScheduler.
- CheckpointCoordinator, responsible for the Checkpoint process control of the job.
- ResourceManager is responsible for the application and management of job resources. It currently supports Standalone mode and will support On Yarn and On K8s in the future.
- Metrics Service, responsible for the statistics and summary of job monitoring information.
TaskExecutionService
TaskExecutionService is the Worker service of the cluster, which provides the real runtime environment of each Task in the job. TaskExecutionService uses Dynamic Thread Sharing technology to reduce CPU usage.
SlotService
SlotService runs on each node of the cluster and is mainly responsible for the division, application, and recycling of resources on the node.
04 Unique advantages and features
Autonomous cluster
SeaTunnel Engine has realized autonomous clustering (no centralization). To achieve cluster autonomy and job fault tolerance without relying on third-party service components (such as Zookeeper), SeaTunnel Engine uses Hazelcast as the underlying dependency. Hazelcast provides a distributed memory network, allowing users to operate a distributed collection like a normal Java collection locally. SeaTunnel saves the status information of the job in the memory grid of Hazelcast. When the Master node switches, it can Job state recovery based on data in the Hazelcast in-memory grid. At the same time, we have also implemented the persistence of Hazelcast memory grid data, and persisted the job status information to the storage (database of JDBC protocol, HDFS, cloud storage) in the form of WAL. In this way, even if the entire cluster hangs and restarts, the runtime information of the job can be repaired.
Data cache
SeaTunnel Engine is different from the traditional Spark/Flink computing engine, it is an engine specially used for data synchronization. The SeaTunnel engine naturally supports data cache. When multiple synchronous jobs in the cluster share a data source, the SeaTunnel engine will automatically enable the data cache. The source of a job will read the data and write it into the cache, and all other jobs will no longer read data from the data source but are automatically optimized to read data from the Cache. The advantage of this is that it can reduce the reading pressure of the data source and reduce the impact of data synchronization on the data source.
Speed control
SeaTunnel Engine supports the speed limit during data synchronization, which is very useful when reading data sources with high concurrency. A reasonable speed limit can not only ensure that the data is synchronized on time, but also minimize the pressure on the data source.
Shared connection pool to reduce database pressure
At present, the underlying operating tools and data synchronization tools provided by computing engines such as Spark/Flink cannot solve the problem that each table needs a JDBC connection when the entire database is synchronized. Database connections are resources for the database. Too many database connections will put great pressure on the database, resulting in a decrease in the stability of database read and write delays. This is a very serious accident for business databases. To solve this problem, SeaTunnel Engine uses a shared connection pool to ensure that multiple tables can share JDBC connections, thereby reducing the use of database connections.
Breakpoint resume (incremental/full volume)
SeaTunnel Engine supports resumed uploads under offline synchronization. When the amount of data is large, a data synchronization job often needs to run for tens of minutes or several hours. If the middle job hangs up and reruns, it means wasting time. SeaTunnel Engine will continue to save the state (checkpoint) during the offline synchronization process. When the job hangs up and reruns, it will continue to run from the last checkpoint, which effectively solves the data that may be caused by hardware problems such as node downtime. Delay.
The Schema revolution route
Schema evolution is a feature that allows users to easily change a table's current schema to accommodate data that changes over time. Most commonly, it is used when performing an append or overwrite operation, to automatically adjust the schema to include one or more new columns.
This capability is required in real-time data warehouse scenarios. Currently, the Flink and Spark engines do not support this feature.
Fine-grained fault-tolerant design
Flink's design is fault tolerance and rollback at the entire job level. If a task fails, the entire job will be rolled back and restarted. The design of SeaTunnel Engine takes into account that in the data synchronization scenario, in many q cases, the failure of a task should only need to focus on fault tolerance for tasks that have upstream and downstream relationships with it. Based on this design principle, SeaTunnel Engine will first generate a logical DAG according to the user-configured job configuration file, then optimize the logical DAG, and finally generate a pipeline (a connected subgraph in a job DAG) to call and execute jobs at the granularity. fault tolerance.
A typical usage scenario is:
Use the CDC connector to read data from MySQL's binlog and write it to another MySQL. If you use Flink or Spark engine, once the target MySQL cannot write, it will cause the task of CDC to read the binlog to be terminated. If MySQL is set If the expiration time of the log is set, the problem of the target MySQL is solved, but the log of the source MySQL is cleared, which leads to data loss and other problems.
SeaTunnel Engine will automatically optimize this synchronization task, automatically add the source to the target Cache, and then further optimize this job into two Pipelines, pipeline#1 is responsible for reading data from the CDC and writing it to the SeaTunnel Cache, and pipeline#2 is responsible for reading data from the SeaTunnel Cache Cache reads data and writes to target MySQL. If there is a problem with the target MySQL and cannot be written, the pipeline#2 of this synchronization job will be terminated, and the pipeline#1 will still run normally. This design fundamentally solves the above problems and is more in line with the processing logic of the data synchronization engine.
Dynamically share threads to reduce resource usage
SeaTunnel Engine's Task design uses shared thread technology. Different from Flink/Spark, SeaTunnel Engine does not simply allow a Task to occupy a thread, but through a dynamic perception method - Dynamic Thread Sharing (Dynamic Thread Sharing) To judge whether a Task should share a thread with other Tasks or should monopolize a thread.
Compared with single-threaded serial computing, multi-threaded parallel computing has better performance advantages, but if each Task uses an independent thread to run, when there are many tables for data synchronization and the number of Tasks is large, it will be in the Worker node Start very many threads on it. When the number of CPU cores is fixed, the more threads, the better. When the number of threads is too large, the CPU needs to spend a lot of time on thread context switching, which will affect computing performance.
Flink/Spark usually limits the maximum number of tasks running on each node. In this way, it can avoid starting too many threads. To run more tasks on one node, SeaTunnel Engine can share thread technology. Let those tasks with a small amount of data share threads, and tasks with a large amount of data exclusively use threads. This method makes it possible for SeaTunnel Engine to run hundreds or thousands of table synchronization tasks on one node, with less resource occupation. Complete the synchronization of more tables.
05 Basic functions and features
2.3.0 is the first official version of SeaTunnel Engine, which implements some basic functions. For the detailed design, please refer to: https://github.com/apache/incubator-seatunnel/issues/2272
[ Cluster Management ]
- Support stand-alone operation
- Support cluster operation
- Autonomous cluster (no centralization), no need to specify a Master node for the SeaTunnel Engine cluster, SeaTunnel Engine elects the Master node by itself during operation and automatically selects a new Master node after the Master node hangs up.
- Automatic discovery of cluster nodes, the nodes with the same cluster_name will automatically form a cluster.
[ Core function ]
- Supports running jobs in Local mode. The cluster is automatically destroyed after the job runs.
- It supports running jobs in Cluster mode (single machine or cluster) and submitting jobs to the SeaTunnel Engine service through SeaTunnel Client. After the job is completed, the service continues to run and waits for the next job submission.
- Support offline batch synchronization.
- Support real-time synchronization.
- Batch and flow integration, all SeaTunnel V2 version connectors can run in SeaTunnel Engine.
- Supports distributed snapshot algorithm cooperates with SeaTunnel V2 connector to support two-phase commit, and ensures data exactly-once.
- Supports job invocation at the Pipeline level to ensure that it can be started even when resources are limited.
- Supports job fault tolerance at the Pipeline level. The failure of a Task only affects the Pipeline it is in, and only the Task under the Pipeline needs to be rolled back.
- Supports dynamic thread sharing to achieve real-time synchronization of a large number of small data sets.
06 Future optimization plan
- Support Cache mode, and first support Kafka as Cache
- Support JobHistory, support the persistence of JobHistory.
- Support indicator (Reader Rows, QPS, Reader Bytes) monitoring and indicator query
- Support dynamic modification of the execution plan.
- Support CDC.
- Support whole database synchronization
- Support multi-table synchronization
- Support for Schema Revolution